Часть I. Язык С
Первые главы этого части диска носят ознакомительный и довольно элементарный характер. Во-первых, мы расскажем об основных принципах работы компьютера и о процессе создания новой программы. Во-вторых, покажем, как упомянутый процесс реализуется при работе с C++Builder.
После этого мы перейдем к описанию языка С, послужившего основой для разработки C++. Знание непосредственного предшественника языка, изучению которого посвящена книга, представляется необходимым. Освоение С, а затем C++ — естественный путь обучения, хотя, конечно, возможны и другие подходы к этому вопросу. Например, можно было бы начать сразу с классов и объектов, но такая методика потребовала бы как от автора, так и от читателя (который, как предполагается, имеет некоторое представление о традиционном программировании) изменения “интуитивного подхода к окружающему миру”, если выражаться несколько высокопарно. Короче, переход на объектно-ориентированную технологию программирования — процесс непростой, и мы решили пойти традиционным путем, представив сначала краткий курс по языку С; и только потом, в части II, мы займемся собственно программированием на C++.
Естественно, тем читателям, кто хорошо знает С, достаточно будет только просмотреть эти главы книги, хотя совсем игнорировать их мы не рекомендуем.
Глава 1. Основные принципы и понятия
Поскольку книга, как предполагается, адресована широкому кругу читателей, в том числе и новичкам, мы начнем с самых элементарных вещей. И прежде всего с того, как вообще организованы вычисления (в широком смысле слова) на компьютере.
Немного теории и терминологии
Что собой представляет персональный компьютер? Если говорить о его устройстве, то в нем имеется центральное процессорное устройство (CPU), процессор плавающей арифметики, оперативная память (RAM), кэш-память, постоянная память (ROM) с зашитыми в ней подпрограммами BIOS, контроллеры внешних устройств (дисков, клавиатуры, дисплея и т.д.)... В общем, это весьма сложная система, которая, по-видимому, должна производить обработку данных.
С точки зрения программиста все выглядит несколько проще. Программисту нет дела, например, до кэш-памяти — это “прозрачный” буфер между процессором и основной памятью. Процессорное устройство — это просто набор регистров, содержимое которых интерпретируется и изменяется (в частности, вследствие обмена данными с памятью) на каждом шаге того процесса, который называют исполнением программы. Отдельный шаг — это исполнение машинной инструкции. Инструкции по очереди извлекаются из памяти машины.
Может быть, не все знают, что современные компьютеры, если рассматривать их абстрактно, являются так называемыми машинами фон Неймана. Это означает, что программа, т.е. машинные инструкции, и данные, которые машина должна обрабатывать (числа, текст и т.п.), физически никак не отличаются друг от друга и хранятся в одной и той же оперативной памяти. В каком качестве — инструкций или данных — будет интерпретироваться та или иная информация, зависит от контекста, наличного в данный момент времени. Пока программа обрабатывается компилятором, сохраняется на диске или загружается операционной системой в память, она — “данные”. Только когда программа загружена и операционная система передает управление на ее входную точку, она начинает интерпретироваться как собственно программа, состоящая из инструкций.
В качестве текущей инструкции берется содержимое той ячейки памяти, адрес которой содержится в регистре — указателе инструкций(ip). После исполнения инструкции этот регистр либо получит приращение и будет указывать на следующую по порядку инструкцию, либо будет загружен новым значением, не связанным с предыдущим, что приведет к передаче управления в другую часть программы (это происходит чаще всего при вызове процедуры). При вызовах процедур и функций очень важен еще один регистр — указатель стека (SP). О нем нам еще придется говорить в дальнейшем.
Нам, как программистам, пишущим на C++, нужно очень хорошо представлять себе логическую организацию памяти компьютера, поскольку в этом языке чрезвычайно большую роль играют указатели и ссылки, а также динамическое распределение памяти. Логически память представляет собой непрерывную последовательность 8-битных байтов, идентифицируемых своими адресами. Если некоторый объект (в широком смысле слова — число, строка, структура и т.д.) занимает несколько байтов, то его адресом будет являться адрес его младшего (начального) байта. Адрес на машинах класса Pentium — это, по существу, 32-битное целое число без знака. Указатель (или ссылка) фактически является переменной, которая содержит целое число, представляющее адрес другого объекта.
Важнейшей технической характеристикой компьютера является его разрядность. Разрядность определяется размером регистров процессора; это — размер порции данных, которую процессор способен обработать за один раз, при исполнении одиночной инструкции. Мы с вами будем говорить о программировании 32-битных машин семейства Pentium в той мере, в какой это, будет относиться к конкретным программам, создаваемым с помощью C++Builder; что касается стандартов языка C++, не имеет значения, на какой машине вы работаете.
На практике прикладному программисту не приходится иметь дела с машинными инструкциями и прочими “низменными материями” — он пишет программу на языке высокого уровня, таком, как C++ или Pascal. Заботу об управлении внешними устройствами берет на себя операционная система, оснащенная соответствующими драйверами, в нашем случае — 32-битная система Windows (NT, 95, 98, 2000). Любое устройство графического отображения информации (например, дисплей) представляется контекстом устройства (DC) системы Windows. Действия пользователя (нажатие клавиш, манипуляции мышью) преобразуются системой в события, или сообщения, получаемые прикладной программой. Кстати, Windows и называется системой, управляемой событиями.
Ну вот, мы, кажется, закончили с изложением необходимых сведений об организации персонального компьютера. Этот коротенький параграф может вызвать у читателя недоумение. Мы ввели ряд терминов, по существу никак их не определяя. Честно говоря, все написанное выше предназначено только для того, чтобы просто ввести в обиход некоторые важные слова; что они означают, будет выясняться впоследствии. А теперь мы поговорим о том, как происходит преобразование кода на языке высокого уровня, написанного прикладным программистом, в инструкции процессора, в машинный код, сохраняемый в ехе-файлах системы Windows.
Процесс построения программы
В этом разделе мы опишем “классический” процесс подготовки и трансляции программы на языке высокого уровня (в нашем случае это C++') в исполняемый файл, содержащий машинные инструкции и все остальное, что необходимо для работающей программы системы Windows. В C++Builder, как мы увидим в дальнейшем, детали этого процесса в основном скрыты от программиста и, кроме того, имеются дополнительные моменты, обусловленные спецификой визуального подхода к программированию. Создание программы на языке C++ выглядит примерно так. Прежде всего, программист с помощью того или иного текстового редактора готовит файлы исходного кода на C/C++. После этого происходит построение программы, в котором можно выделить такие этапы:
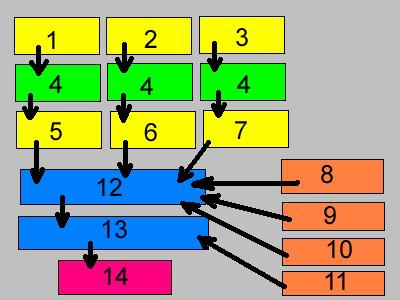
Рис. 1.1 Упрощенная схема построения программы
1. Source1.cpp
2. Source2.cpp
3. Source3.cpp
4. Компилятор
5. Source1.obj
6. Source2.obj
7. Source3.obj
8. Addon.lib
9. Код запуска
10. Исполнительная библиотека
11. Ресурсы App.res
12. Компоновщик
13. Компоновщик ресурсов
14. Приложение App.exe
Некоторые системы (и в том числе C++Builder) сразу выполняют компоновку объектных файлов с ресурсами, совмещая два последних этапа. Что касается первого шага — компиляции — то здесь возникает одна проблема, которую стоит обсудить.
Проблема раздельной компиляции
Когда-то давно программа для машины вроде БЭСМ-4, написанная на языке Алгол-60 или FORTRAN, состояла из одного-единственного файла, а точнее, являлась просто одной “колодой” перфокарт. Также и первые версии языка Pascal для PC (например, Turbo Pascal 2) допускали, по существу, компиляцию только программ, состоящих из единственного исходного файла. Компилятор “видел” сразу весь текст программы и мог непосредственно проконтролировать, например, количество и тип фактических параметров в вызове процедуры, — соответствуют ли они тем, что указаны в заголовке ее определения (формальным параметрам). Компилятор транслировал программу сразу в машинный код (исполняемый файл).
С ростом сложности и объема программ пришлось разбивать их на несколько файлов исходного кода. Соответственно трансляция программы распалась на два этапа — компиляции, на котором каждый из исходных файлов транслируется в файл объектного кода, и компоновки, в результате которой из нескольких объектных файлов получается конечный исполняемый файл. При этом необходимо произвести, как говорят, разрешение адресных ссылок, когда, например, основной файл программы обращается к вспомогательной процедуре, находящейся в другом файле.
Компилятор C/C++ генерирует стандартные объектные файлы с расширением .obj. (Их формат определен фирмой Intel и не зависит от конкретной операционной системы.) Файлы эти содержат машинный код, который снабжен дополнительной информацией, позволяющий компоновщику разрешать ссылки между объектными модулями. Так, в начале файла формируются две таблицы: таблица глобальных символов (это имена объектов, определяемых в данном файле, на которые могут ссылаться другие модули программы) и таблица внешних ссылок (имена объектов в других файлах, к которым обращается данный модуль). Пользуясь информацией этих таблиц, компоновщик модифицирует код, подставляя в него соответствующие адреса.
Проблема состоит в том, что в объектном файле отсутствует информация, которая позволяла бы проверить корректность вызова процедуры (т.е. количество и тип ее параметров), находящейся в другом файле. Ведь компилятор обрабатывает файлы исходного кода по отдельности.
В языке Turbo Pascal (и позднее — в Delphi) эта проблема была решена благодаря определению специального формата промежуточных файлов. Эти “объектные” файлы (в Delphi они имеют расширение ,dcu) содержат, помимо всего прочего, информацию о параметрах процедур и функций, об определяемых в модуле типах данных (классах) и т.д.
C/C++ был задуман как максимально универсальный язык, и потому он не может использовать нестандартный формат объектных файлов. Это сделало бы невозможным, например, создание файлов подпрограмм, которые могли бы включаться в программы, написанные на других языках. Возможность раздельной компиляции обеспечивается в C/C++ применением заголовочных файлов, присоединяемых к компилируемым исходным файлам на этапе препроцессорной обработки. Заголовки содержат прототипы функций, объявления типов и другую информацию, необходимую для раздельной компиляции исходных модулей программы.
Заголовочные файлы (они имеют расширение .h или .hpp) подключаются к компилируемому файлу исходного кода (.с или .срр) с помощью директивы препроцессора #include, за которой следует имя заголовочного файла в кавычках или угловых скобках, например:
#include <stdlib.h>
#include "myfile.h"
Препроцессор заменяет директиву #include содержимым указанного файла; после завершения препроцессорной обработки полученный текст передается компилятору, который транслирует его в объектный код.
Во многих системах программирования на C/C++ препроцессор составляет единое целое с компилятором (это верно и для C++Builder). Тем самым ускоряется компиляция исходных файлов, и нет необходимости создавать промежуточный файл, содержащий обработанный препроцессором код. Однако в C++Builder имеется отдельный препроцессор срр32.ехе, запускаемый из командной строки. Вы можете им воспользоваться, если нужно просмотреть текст, получаемый в результате препроцессорной обработки; это может быть полезно, например, при отладке макросов препроцессора. Директивы препроцессора будут подробно рассматриваться в 4-й главе.
Один и тот же заголовок можно подключать ко многим исходным файлам. Таким образом, отдельно компилируемые модули получают доступ к необходимой информации о процедурах и прочих элементах программы, определяемых в других модулях. Кроме того, это гарантирует, что размещенное в заголовочном файле объявление типа или функции будет одним и тем же во всех компилируемых файлах, и любые внесенные в него изменения будут автоматически воздействовать на все модули программы.
О библиотеках
Выше мы уже упоминали о библиотеках, не объясняя, впрочем, что они собой представляют. Конкретнее, мы имели в виду библиотеки объектных модулей; такая библиотека является просто собранием модулей объектного кода, скомпонованных в одном файле с расширением lib, своего рода архивом. На рис. 1.1 показана гипотетическая библиотека пользователя Addon.lib. Она могла бы быть создана из нескольких объектных модулей путем обработки их библиотекарем tlib32.exe.
На рисунке показаны также код запуска и исполнительная библиотека языка C/C++. Это необходимые элементы компоновки любой программы на С. Код запуска исполняется перед тем, как управление будет передано на входную точку вашей программы (функцию main, WinMain и т. п.). Среди задач, им выполняемых, можно указать следующие:
Исполнительная библиотека содержит разнообразные процедуры общего назначения, которые вы можете вызывать в своей программе. В частности, библиотека обеспечивает:
Что касается динамически присоединяемых библиотек — DLL, — то во многих случаях они, с точки зрения программиста, мало чем отличаются от обычных, статически компонуемых библиотек объектных модулей. Функция, которая находится в DLL, вызывается так же, как и всякая другая функция. Правда, “снаружи” динамическая библиотека выглядит скорее как исполняемый файл; эти библиотеки создаются не библиотекарем, а компоновщиком. Вообще-то вопросы разработки и использования DLL выходят за рамки этой книги, но в следующей главе мы приведем пример простейшей DLL, чтобы читатель получил представление о том, как это делается в C++Builder.
Каждая библиотека, как правило, сопровождается своим заголовочным файлом (их может быть и несколько), который определяет интерфейс ее функций и других элементов. Исходный код библиотеки может быть и недоступен для программиста. Но в ее заголовочном файле (или файлах) имеется все необходимое для использования библиотеки в прикладной программе.
Заключение
В этой очень короткой главе мы попытались обрисовать “классический” процесс создания прикладной программы на языке C/C++. По сути наше изложение было ориентировано на то, чтобы дать читателю представление о терминологии, которую мы будем постоянно применять, и создать тем самым некоторый первоначальный контекст, для дальнейшего обсуждения. То, что осталось непонятным, будет проясняться в дальнейшем.